




La “coda paradossale nei supermercati” è stato l’articolo in cui abbiamo raccontato dal punto di vista tecnico quello che sta succedendo di fronte ai nostri supermercati. Successivamente, abbiamo cercato di entrare dentro e provare ad indagare le conseguenze degli scaffali svuotati lungo tutta la supply chain (effetto bullwhip o frusta).
Oggi, assieme, al professore Ivan Russo dell’Università di Verona, Giacomo Marani e Simone Bigi cercheremo di portare il nostro contributo tecnico, condividendo alcune riflessioni e discutendo alcune proposte sul come migliorare il flusso logistico dei tamponi che rilevano il virus, dato che pare inevitabile proseguire e migliorare la strategia di contenimento basata sul testare e tracciare (test and trace).
In particolare, secondo i maggiori esperti, una delle strategie di controllo della diffusione delle pandemie, ed in particolare COVID-19, dipende strettamente dalla capacità di presidio del territorio ed in particolare dalla velocità e dall’efficacia delle contromisure adottate.
Il mondo scientifico sembra concordare sulla necessità di rilevare la diffusione del virus grazie al prelievo sistematico di campioni biologici (tamponi) anche su soggetti asintomatici, i più difficili da segnalare e trovare. Questa misura dovrà essere integrata con il tracing dei casi, se ne sta discutendo in questi giorni, per arrivare all’obiettivo di testare e tracciare i casi e rendere più mirata la strategia di contenimento e poter mitigare il rischio di nuove pesanti ondate di diffusione.
Molte energie sono state allocate per i test (cosiddetti tamponi), con risultati non sempre allineati agli sforzi profusi; sin dai primi giorni della pandemia COVID19 è stato chiaro che il numero di tamponi prelevati fosse insufficiente (o poco mirato) e la capacità di analisi sottodimensionata. Quando si è arrivati al potenziamento della strumentazione di analisi è emerso un secondo problema: come raccogliere e processare tamponi su un territorio vasto e con una “città diffusa”, tipica del sistema di sviluppo di diverse regioni?
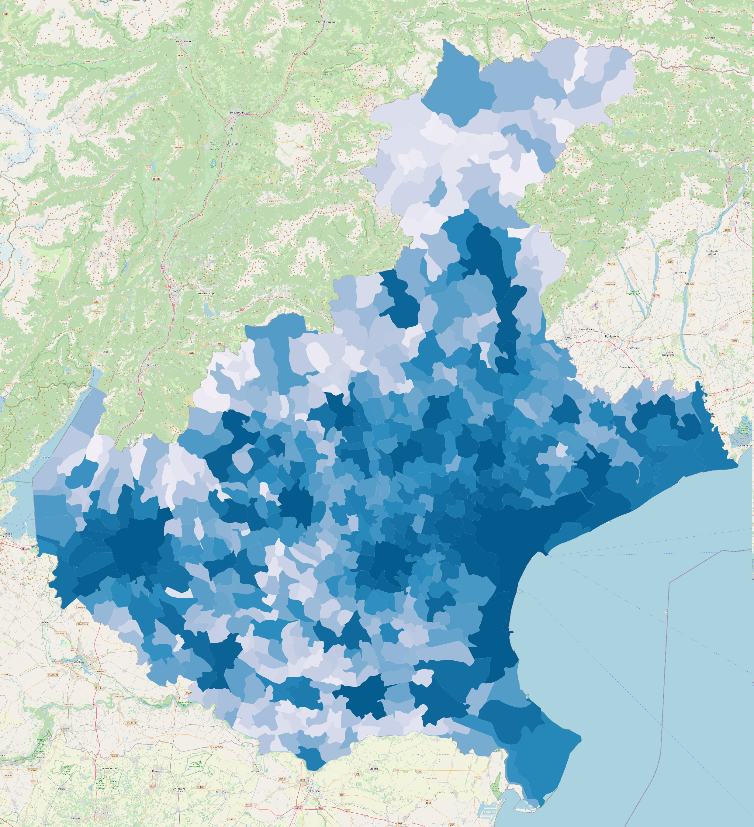
La mappa riportata mostra la distribuzione di densità di popolazione, nei comuni della Regione Veneto, la regione che conosciamo meglio. È necessario, in fase di progettazione di un sistema logistico-distributivo bilanciato, considerare la morfologia del territorio e come i cittadini sono distribuiti su di essa.
Ad oggi, sono stati eseguiti oltre 1,5 milioni di tamponi in Italia, oltre 277 mila nella sola Regione Veneto, oltre 290 mila in Regione Lombardia e oltre 140 mila in Regione Emilia-Romagna e si prospetta un ritmo costante e sostenuto nelle prossime settimane.
Tuttavia, come dicevamo, il numero di tamponi fatti e refertati ogni giorno non sembrano mai sufficienti rispetto all’emergenza e alle necessità. Non è detto che nelle varie Regioni esista sempre una ottimale sincronizzazione dei flussi informativi e fisici per supportare la scelta.
A titolo d’esempio, leggiamo che nella Regione Veneto ogni giorno vengono effettuati circa 334 tamponi ogni 10 mila persone (numero che crescerà) che devono essere successivamente processati, in modo rapido, nei laboratori di riferimento. Tuttavia, attualmente, la capacità “produttiva” dei laboratori è di circa 3000 tamponi al giorno (da notizie di stampa) e la Regione Veneto sta cercando, meritoriamente, di aumentare tale capacità con uno o più termociclatori per reazione a catena della polimerasi (PCR) che ne dovrebbe esaminare più del triplo. È una ottima notizia, coerente con sforzo regionale su questo tema. Attualmente i laboratori in grado di supportare lo sforzo sembrano essere più di dieci in Regione Veneto.
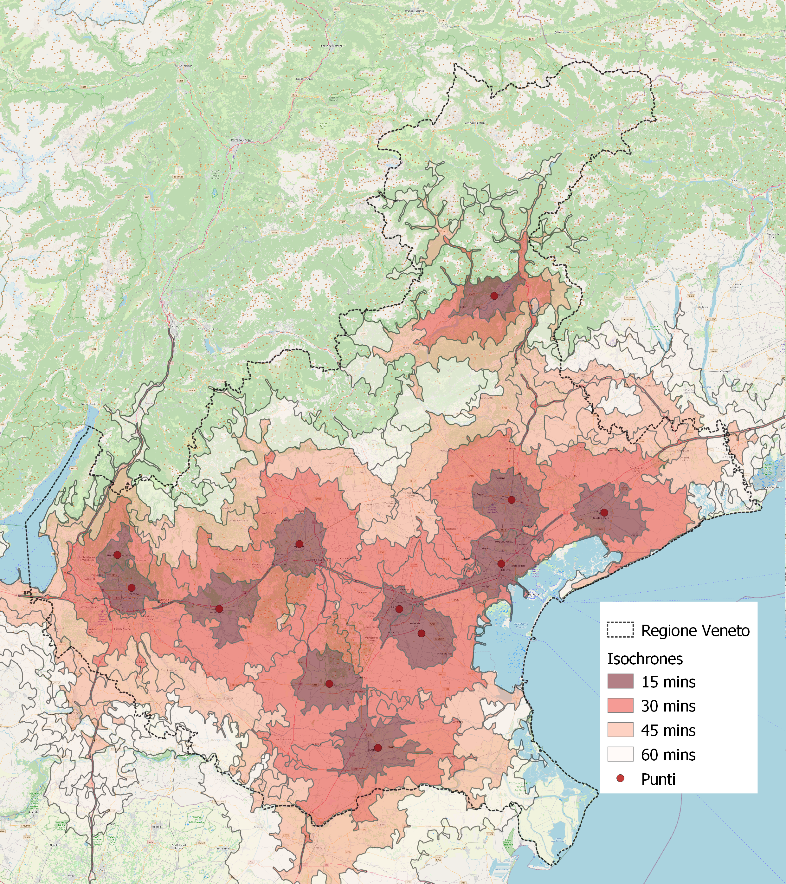
La mappa isocrona riportata sopra mostra la localizzazione dei laboratori e le aree di raggiungibilità stradale in 60 minuti di auto da essi. Se aumenta la capacità produttiva ci auguriamo possa diminuire anche il tempo di presa del tampone. In poche parole: aumentando la capacità produttiva siamo sicuri di aumentare proporzionalmente il numero di tamponi giornaliero? Quale modello possiamo prendere a riferimento per aumentare stabilmente il numero di tamponi prelevati in Veneto ovvero in altre Regioni?
Processo di raccolta e analisi tamponi: inquadramento
Il problema che discutiamo coinvolge decisioni mediche che non ci competono (es. molti pazienti sospetti positivi lasciati in quarantena volontaria senza tamponi ovvero il numero di tamponi per paziente necessari); preferiamo dunque concentrarci sulla seconda parte del problema ovvero come migliorare il flusso di presa dei tamponi.
Possiamo rappresentare sinteticamente il tale flusso di processo in due parti collegate:
- Processo di segnalazione: da segnalazione del paziente a prelievo del campione.
- Processo di raccolta e analisi tamponi: da prelievo del campione a referto.

Per cominciare l’analisi è necessario definire le risorse coinvolte nel processo:
- Personale specialistico e mezzi per fare il prelievo tamponi;
- Luogo di prelievo (in casa oppure in centri di prelievo);
- Mezzi per portare ai laboratori i campioni prelevati;
- Strumentazione di analisi e personale tecnico (laboratori, termociclatori, …);
- Filiera di produzione ed asservimento dei materiali necessari (reagenti, consumabili, …).
Già a questo punto del nostro contributo tecnico possiamo vedere facilmente che la strumentazione di analisi (4), su cui si sono concentrati gli sforzi del primo periodo, non è l’unica risorsa necessaria per raggiungere l’obiettivo (“test, test, test”). Siamo, infatti, di fronte ad un problema di costruzione di un flusso sincronizzato di lavoro, se non di una intera supply chain, piuttosto che di potenziamento di una risorsa singola. Possiamo orientarci nell’analisi riferendoci al grafico sottostante.
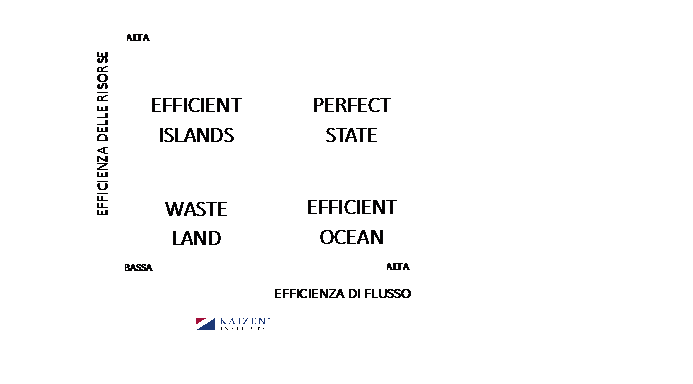
Il flusso logistico ad alte prestazioni: cicli logistici pull e takt delle analisi
“Tutto quello che stiamo facendo è osservare la linea del tempo che va dall’ordine cliente all’incasso… e stiamo riducendo quel tempo rimuovendo le attività che non aggiungono valore” (T. Ohno).
Così si esprimeva il padre del cosiddetto Toyota Production System per raccontare il livello di performance raggiunto dalla sua azienda utilizzando al meglio le risorse disponibili e limitando gli investimenti. Nella logistica dei tamponi potremmo rileggere le sue parole nel modo seguente:
“Tutto quello che stiamo facendo è osservare la linea del tempo che va dal prelievo del test al referto… e stiamo riducendo quel tempo rimuovendo le attività che non aggiungono valore”. In sintesi: cercheremo di rimodellare il flusso del valore per farlo scorrere con gradualità e verso miglioramenti continui. Ricordando che ogni flusso ha due tipi di attività: attività che creano valore e attività che non creano valore (i cosiddetti muda). Alcuni di questi si possono eliminare o ridurre con l’evoluzione del modello organizzativo, altri richiederebbero anche un forte salto tecnologico per essere rimossi e vanno gestiti.
Inoltre, ricordiamo che è inutile rinforzare il singolo anello di una catena per aumentarne la resistenza, è inutile creare un’isola di efficienza sperando di migliorare l’intero processo. La prima “tentazione” nel miglioramento organizzativo è, infatti, quella di investire per aumentare l’efficienza di una parte del processo, la strumentazione di analisi in questo caso, passando appunto dall’inefficienza iniziale (waste land) alla disponibilità della nuova strumentazione “performante” (efficient island). Una volta installato l’impianto o nuovo macchinario (termociclatori) però, spesso emergono dei bottle neck che ne impediscono l’uso ottimale ed i risultati pianificati non arrivano. Sicché appare chiaro che il flusso di lavoro va migliorato globalmente ed è necessario passare da efficienza di risorse ad efficienza di flusso.
Per comprendere meglio questo concetto possiamo utilizzare la metafora dell’organizzazione di una pizzeria. Raddoppiare il forno velocizza il servizio solo se si dimensiona correttamente l’intero servizio (cuochi, camerieri, tavoli, consegne).
A questo punto dobbiamo comprendere la sostenibilità nel tempo delle misure adottate. Raggiungere l’efficienza di flusso può all’inizio penalizzare le risorse impiegate ed il modello appare molto costoso: nella nostra pizzeria potremmo sostenere l’investimento fatto destinando un cameriere ad ogni tavolo per garantire il servizio ottimale in fase di start-up e rimuovere i bottle-neck, ma alla lunga il modello non regge economicamente. Esattamente come nell’esempio, l’iniziale disponibilità di risorse infinite (o quasi) data l’emergenza per costruire raggiungere il numero di tamponi/giorno necessari, si scontrerà presto con i vincoli di bilancio, soprattutto perché il tempo di monitoraggio sembra sarà prolungato per molti mesi. Dobbiamo allora tornare a migliorare l’efficienza delle singole risorse, in modo da poter costruire un modello stabile e sostenibile per prevenire la diffusione anche di future focolai o addirittura di future pandemie.
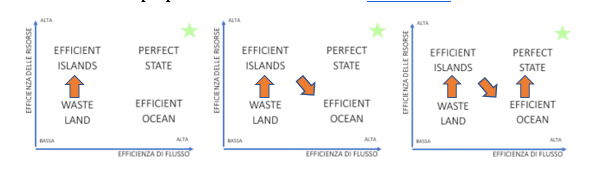
Siamo arrivati a dover costruire un intero flusso logistico capace di collettare i tamponi sul territorio ed analizzarli in modo efficiente. È utile, ora, definire il concetto di efficienza di flusso, strettamente collegata al valore generato dal processo stesso. L’efficienza di flusso è il rapporto il valore generato lungo tutto il flusso ed il totale delle risorse impiegate nello stesso; tutto il resto è muda (non valore o impropriamente chiamato spreco).
Nel nostro caso si crea valore quando si preleva il tampone dal paziente/cittadino, quando lo si analizza e lo si referta. Tutte le altre attività (es. i trasporti, i ritardi nella consegna dei tamponi, l’attesa di tamponi a macchina ferma, l’assenza di reagenti o materiale necessario per le analisi etc.) sono muda (non generano valore!) e vanno ridotti perché consumano una risorsa chiave: il tempo del personale addetto al prelievo oppure la capacità di analisi della macchina.
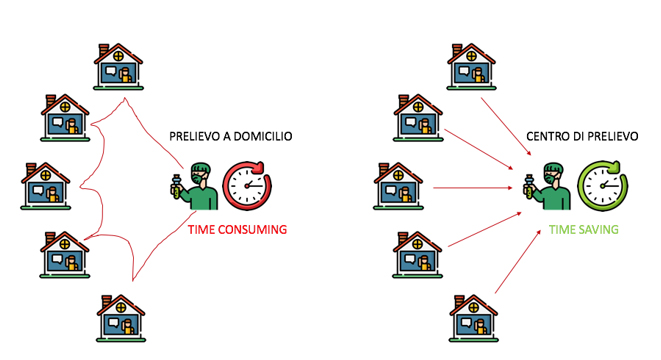
Da questa osservazione possiamo desumere che il prelievo “casa per casa” è una soluzione ad efficienza minore del prelievo in ipotetici “centri di raccolta” (es. drive-in, già in opera in alcune città): molto del tempo del personale addetto al prelievo sarebbe, infatti, consumato nei trasferimenti.
La nostra proposta di gestione efficiente è applicabile ai campionamenti routinari da fare su larga scala a soggetti non ancora colpiti dall’infezione e liberi di muoversi verso i cosiddetti centri di raccolta. Per tutti gli altri è necessario l’intervento a domicilio, costi quello che costi.
Questa ultima considerazione rafforza ancor più la necessità di agire in anticipo: il campionamento su soggetti non ancora impossibilitati a muoversi in autonomia è molto più oneroso. L’assunzione di base che facciamo è che la raccolta del tampone sia fatta necessariamente da personale specializzato, non delegabile all’auto test da parte del paziente (come avviene in diverse parti del mondo). La modifica di questa premessa, che venisse a far cadere l’impegno di personale specializzato aprirebbe uno scenario logistico molto più semplice e renderebbe possibile utilizzare modelli organizzativi diversi, come ad esempio la consegna/prelievo a domicilio fatta da un corriere logistico.
Un possibile flusso efficiente e a valore
Nelle condizioni sopracitate un flusso efficiente dovrebbe essere organizzato in quattro fasi:
- Centri di prelievo sul territorio
- Trasferimento al/ai laboratori di analisi
- Analisi di laboratorio
- Refertazione
Ogni fase va correttamente dimensionata per garantire una efficacia sincronizzazione. È fondamentale definire sia il numero di centri prelievo (in relazione alla densità di popolazione), sia il numero di laboratori necessari (in relazione al volume di campioni richiesto).
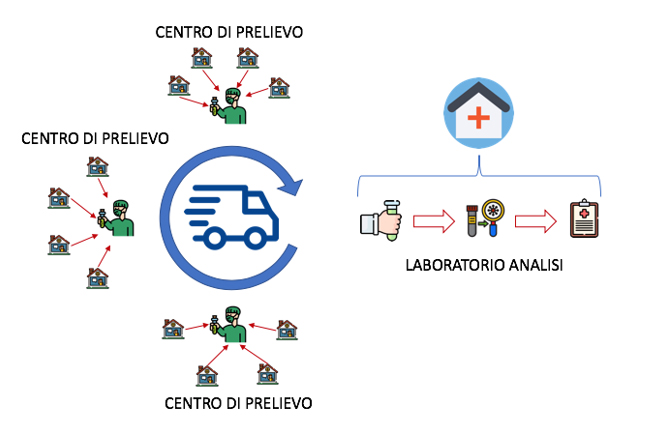
Il percorso di dimensionamento del modello organizzativo dovrebbe essere il seguente:
- Il primo passo è definire la richiesta di campioni/giorno tali da garantire il presidio del territorio nel tempo, considerando il fatto che dovremmo “ri-campionare” le stesse persone almeno 3 volte (prima diagnosi, tampone finale 1 e tampone finale 2). Un utile indicatore in questo ambito è l’EPEI, che identifica l’intervallo di campionamento necessario per tipologia di utente: si potrebbe definire un EPEI differenziato a seconda del rischio connesso alla professione/età. Anche la tecnica utilizzata per selezionare il campione ha un forte impatto sul costo del sistema. Se, a parità di significatività e mitigando eventuali bias, il campionamento venisse focalizzato su una popolazione geograficamente vicina (es. tutti gli impiegati di una fabbrica) il costo dello stesso diminuirebbe molto rispetto ad una popolazione completamente casuale.
- A questo punto dobbiamo definire il concept del centro di prelievo: quanti campioni/ora si riescono a raccogliere in un centro di prelievo e quante persone sono necessarie? La localizzazione dei centri di prelievo va fatta considerando la densità di popolazione. Suggeriamo di progettare centri di prelievo piccoli e molto distribuiti sul territorio per diminuire le concentrazioni di persone in attesa e non richiedere lunghi viaggi alle persone per fare un prelievo. Sono anche preferibili unità mobili perché più facili da ricollocare velocemente in caso di necessità (es. il verificarsi di un nuovo focolaio richiede di concentrare i prelievi all’interno di un’area geografica molto ristretta).
- In terza battuta dobbiamo dimensionare i laboratori, il vero pacemaker o risorsa chiave dell’intero processo: quanti macchinari/consumabili per l’analisi sono necessari per soddisfare la richiesta, e quanto personale tecnico? Il numero di macchinari dipende dal tempo di analisi e dal numero di analisi (batch) possibili per singolo ciclo di lavoro. Un indicatore è sicuramente il numero di campioni/ora e campioni/giorno. Naturalmente va considerato anche il numero di tecnici di laboratorio ed il dimensionamento dello stock dei materiali consumabili necessari al processo. Qual è il right sizing di un laboratorio? Un laboratorio sottodimensionato non garantisce la sostenibilità dei costi, un laboratorio sovra-dimensionato potrebbe essere complesso da gestire. Dunque, va introdotto il concetto di unità di laboratorio efficiente (es. un macchinario con tre tecnici analisti e una scorta standard di materiali).
- Una volta definita l’unità di laboratorio efficiente dobbiamo scegliere il modello logistico-organizzativo più performante per collegare tutte le risorse del processo. Concentrare tutte le analisi in un unico laboratorio oppure dislocare i laboratori nel territorio per essere più vicini ai punti di prelievo. Se una singola unità di laboratorio efficiente serve tutta la regione, allora dobbiamo concentrare la logistica in un unico punto allungando la distanza media percorsa dai mezzi ed il Lead Time del processo; se invece fossero necessarie più unità, queste potrebbero essere distribuite strategicamente collocandoli al centro delle aree isocrone (ossia che garantiscono il rifornimento entro un tempo standard). La seconda soluzione è preferibile perché più adatta al modello di sviluppo diffuso del Veneto e probabilmente anche per altre regioni italiane.
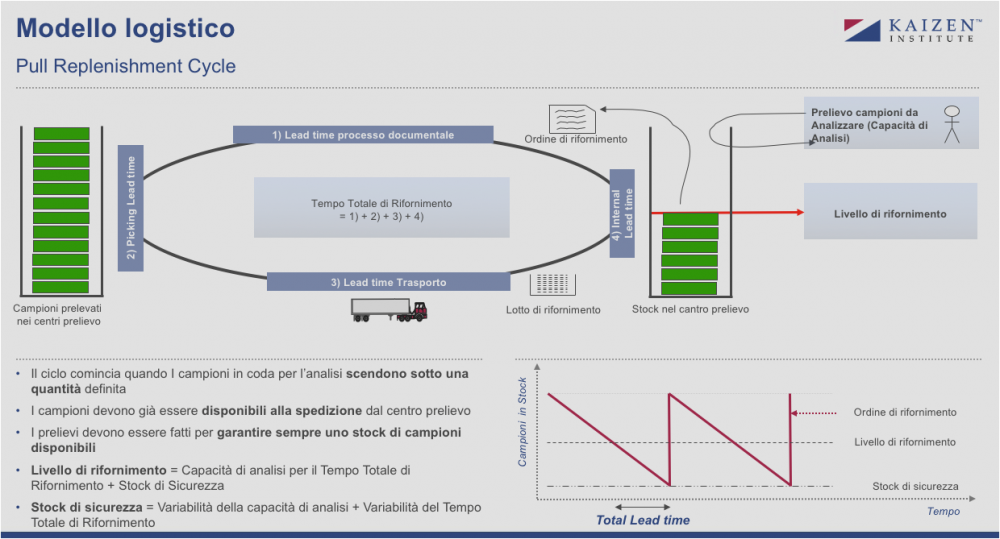
- Il funzionamento della logistica viene definito di conseguenza. Rifornire i laboratori richiede di organizzare dei milk-run che collettino i tamponi dai vari centri di prelievo con un takt time stabile, garantendo il livellamento orario del numero di tamponi in arrivo e stabilizzando lo standard WIP (Work in Progress) a monte del processo, per garantire la massima efficienza delle analisi e il Lead Time. Se gli arrivi sono superiori rispetto alla capacità oraria di analisi, il sistema si intasa (collo di bottiglia o bottle neck) ed il Lead Time si allunga; nel caso contrario si perde capacità produttiva per mancanza di tamponi. I mezzi di trasporto e la loro capacità vanno dimensionati di conseguenza per collegare in maniera efficiente i laboratori.
Il modello logistico sin qui impostato va ora rifinito per evitare un altro tipo di muda, dovuto alla modifica temporanea del numero di analisi richieste in uno specifico territorio (es. la scoperta di un focolaio concentra la necessità di prelievo). Tale circostanza sovraccarica alcune strutture di prelievo ed analisi e ne alleggerisce delle altre. È un problema di livellamento della domanda. Di qui la necessità di costruire un milkrun logistico capace di ridistribuire il carico di lavoro in modo ordinato anche su territori diversi da quelli definiti nello standard iniziale del modello. Quest’ultima è una ipotesi verosimile rispetto alle fasi 2 e 3 immaginate da alcuni che prevedono uno stop and go periodico rispetto all’andamento del contagio.
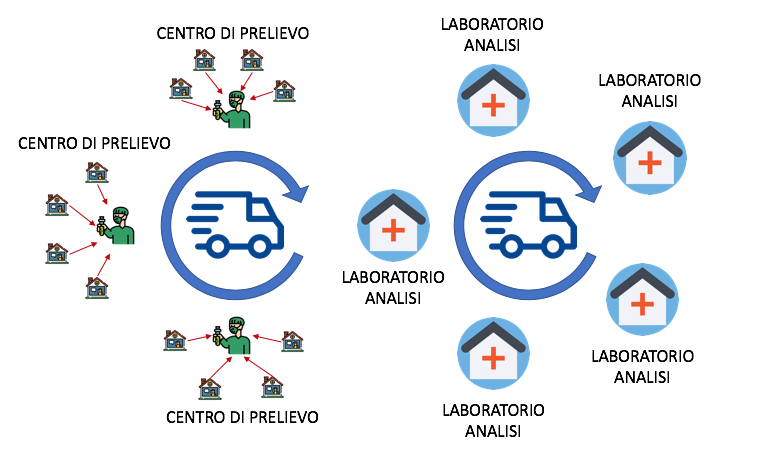
Molto utile sarebbe una costante condivisione dei dati e delle informazioni tra e per i laboratori per permettere un aggiustamento della capacità produttiva, anche e soprattutto collaborando tra regioni confinanti con il vincolo delle aree isocrone (ossia che garantiscono il rifornimento entro un tempo standard). Quindi, si ritiene indispensabile immaginare una control tower dei flussi fisici, informativi e documentali che ottimi il processo che dovrà essere per ragioni ovvie resiliente rispetto all’andamento non facilmente predicibile del contagio.
N.B. abbiamo dovuto basare il modello sulle informazioni note e pubbliche, quindi da affinare con una maggior granularità dei dati, altri elementi potrebbero emergere discutendo direttamente con chi lavora sul campo tra enormi sforzi e fatica. È una proposta tecnica, ogni commento costruttivo è benvenuto.








